.jpg)












你的OpenClaw是不是有点呆,几步调教让你的 AI 助手脱胎换骨

大部分人部署完 OpenClaw 之后,看到它能在 Discord 或 Telegram 里正常回复消息,就觉得已经用上龙虾了。实际上,出厂设置的 OpenClaw连它五分之一的实力都没发挥出来。
真正的潜力,隐藏在那些你没动过的配置文件里。
出厂设置 vs 调教好
让我先用一个对比表格感受下差异:
-j1w0.PNG)
接下来我会按照从易到难、从基础到进阶的顺序,讲解五个关键配置方向。
第一步:塑造个性化的对话风格
OpenClaw 的 workspace 目录下有三个定义“身份”的文件:
SOUL.md — 定义它是谁,回复风格
IDENTITY.md — 设定名称、形象标识
USER.md — 你是谁,它怎么称呼你
大多数人安装后这三个文件基本是空的,所以 AI 只能用最通用的方式回复你——也就是那种“非常荣幸为您服务”的客服腔。
在 SOUL.md 中,我写入了这样的行为准则:
#核心原则
## 沟通风格
- 直接切入主题,不需要礼貌性寒暄
- 允许表达观点,不必保持绝对中立
- 简洁优先,但涉及技术细节时不省略关键信息
## 工作方式
- 优先尝试自主解决,确实需要时再询问
- 主动提供相关背景信息和替代方案就这么简单几行,它的回复风格立马变成正常人说话。
IDENTITY.md 比较简单——给它一个具体的名字和符号标识。这看起来是小事,但在长期使用中,一个有明确身份的 AI 在多轮对话中的表现一致性会明显更好。
USER.md 里记录你的工作时区、技术背景、沟通习惯、职业等。这能避免很多不必要的误解——比如它不会在你的休息时间发送非紧急通知,也不会向一个前端工程师推荐后端框架。
第二步:构建结构化的记忆系统
这是提升体验最显著的一个环节。
默认的 MEMORY.md 文件存在两个问题:要么被闲置,要么变成一个什么都往里塞的垃圾场。真正有效的记忆系统需要分层设计:
MEMORY.md ← 核心索引:只记录关键信息和文件引用
memory/
├── projects.md ← 项目状态和任务追踪
├── infra.md ← 基础设施配置速查
├── lessons.md ← 问题记录和解决方案
└── 2026-02-23.md ← 每日对话日志MEMORY.md 只做索引,不堆积内容。 每次会话启动时只加载这个索引文件,需要具体信息时再按需读取相关文件。这样既保证了启动速度,又不会丢失重要信息。
语义检索能力
配合 OpenClaw 的 memorySearch 功能,你可以实现真正的“语义记忆”:
当你说“上次那个部署失败的问题”, AI 不需要逐行扫描所有历史记录,而是通过语义理解直接定位到相关的那一段对话。
在 openclaw.json 中加上:
"memorySearch": {
"enabled": true,
"provider": "openai",
"remote": {
"baseUrl": "你的embedding服务地址",
"apiKey": "你的密钥"
},
"model": "BAAI/bge-m3"
}SiliconFlow提供的免费 embedding 服务(bge-m3 模型),基本可以零成本实现语义记忆。
另外建议开启 compaction.memoryFlush 选项,这样当对话上下文接近上限时,AI 会自动将重要信息提取到当天的日志文件中,避免因为 token 限制导致的“失忆”。
第三步:通过 Skill 扩展实用功能
OpenClaw 预装了一些基础 skill(天气查询、新闻摘要等),但它的真正威力在于你可以根据自己的需求定制功能模块。
Skill 的本质是一个指导文档(SKILL.md)加上可选的执行脚本。当 AI 识别到相关请求时,会自动读取对应的 SKILL.md 并按照其中的步骤执行。
我目前在使用的几个自定义 skill:
媒体下载器: 发送视频链接,自动下载并生成分享链接
PPT生成器: 根据主题自动生成PPT
量化分析: 输入token,运行预测模型并给出分析报告
x新闻热点: 每天自动收集x热点
一个标准的 skill 目录结构:
skills/
my-skill/
SKILL.md ← AI 的执行指南
execute.sh ← 可选的自动化脚本
README.md ← 可选的使用说明编写要点
在 SKILL.md 中需要明确三个要素:
触发条件 — 什么情况下启用这个 skill
执行流程 — 分步骤的详细操作指南
输出规范 — 结果应该以什么格式呈现
关键是把 AI 当作一个刚入职的助手——你的指令越清晰具体,执行结果就越稳定可靠。模糊的描述会导致不可预测的行为。
社区也有现成的 skill 资源可以参考:clawhub.com
第四步:启用心跳机制实现主动服务
OpenClaw 有一个容易被忽视但非常实用的功能:心跳(Heartbeat)机制。
系统会定期(默认 30 分钟)向 AI 发送一个信号,询问是否有需要处理的事项。默认情况下,AI 只会简单回复 HEARTBEAT_OK 然后什么都不做。
但如果你创建一个 HEARTBEAT.md 文件,就可以定义它在心跳时应该执行的检查任务:
# HEARTBEAT.md
## 每次心跳时执行
- 检查核心服务健康状态(通过 HTTP 探测)
- 如果发现异常,立即通知但不要自动干预
## 每日执行一次
- 扫描项目待办列表,标记超过 3 天未更新的任务
## 每周执行一次
- 整理过去 7 天的对话日志,提炼关键信息到长期记忆这样你的 AI 就变成了一个全天候的监控助手。你休息的时候它在巡检,你上线就能看到整理好的报告。
心跳 vs 定时任务
心跳适合: 轻量级的周期性检查,可以批量执行多个小任务
cron 适合: 需要精确时间触发的独立任务(例如“每周一上午 9 点生成周报”)
第五步:配置模型分级降低成本
如果你通过 API 中转服务可以访问多个模型,强烈建议配置模型分级策略:
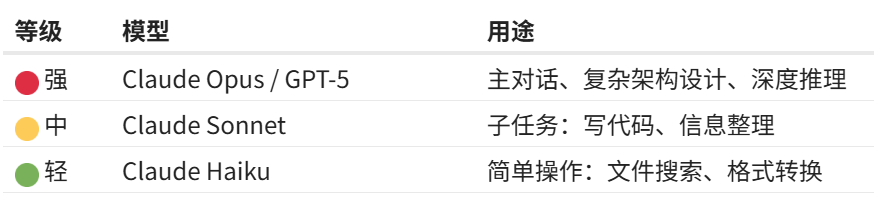
在 openclaw.json 中设置别名:
"models": {
"provider/strong-model": { "alias": "opus" },
"provider/medium-model": { "alias": "sonnet" },
"provider/light-model": { "alias": "haiku" }
}然后在 AGENTS.md 中定义分配规则,AI 在派发子任务时会自动选择合适的模型。
实际效果: 在保持服务质量的前提下,token 消耗可以降低 60-70%,因为绝大多数日常操作根本不需要最强大的模型。
配置优先级清单
按照投入产出比排序:
✅ 完善 SOUL.md / IDENTITY.md / USER.md (10 分钟,效果立竿见影)
✅ 建立分层记忆结构,启用 memorySearch (30 分钟)
✅ 配置 HEARTBEAT.md (10 分钟)
✅ 根据需求安装或编写 2-3 个常用 skill (按需投入)
✅ 配置模型分级策略 (如果有多模型访问权限)
✅ 完善 AGENTS.md 中的行为规范和安全策略
结语
OpenClaw 的设计理念是提供一个灵活的框架,由使用者来定义它的具体形态。默认配置只是一个起点,真正的价值在于你如何根据自己的工作流程来调教它。
我自己经过一段时间的调整,已经把它从一个简单的聊天机器人改造成了一个能够记住上下文、主动执行巡检、协助编码和文档生成的全方位助手。
如果你也在使用 OpenClaw,欢迎分享你的经验和小技巧
让我们的龙虾,一起进化!
进阶阅读: