.jpg)












OpenClaw 从中级到高级完整教程
.PNG)
目录
教程说明:适合谁学习
学习路线:从基础到进阶
核心配置:AGENTS.md 工作规范
记忆优化:构建可靠的记忆体系
子 Agent 应用:团队协作模式
定时任务:Cron 自动化实践
Skill 开发:扩展 AI 能力
多渠道部署:全平台接入方案
性能调优:配置参数详解
实战练习清单
疑难解答
进阶学习资源
教程说明:适合谁学习
学习前提
本教程面向已经完成 OpenClaw 基础配置的用户。在开始之前,请确认你已经:
✅ 成功安装 OpenClaw 并能正常运行✅ 完成基本配置文件的创建(SOUL.md / USER.md / IDENTITY.md)✅ 了解记忆系统的基本概念(MEMORY.md 和 memorySearch)✅ 熟悉 workspace 目录结构✅ 具备基本的命令行操作能力
如果上述条件尚未满足,建议先阅读 你的OpenClaw是不是有点呆, 几步调教让你的 AI 助手脱胎换骨
技术要求
OpenClaw 已安装并正常运行
至少一个 AI 模型 API(Claude 或 GPT)
理解 JSON 和 Markdown 格式
基本的文件系统操作能力
你将学到什么
完成本教程后,你的 OpenClaw 将实现以下能力提升:
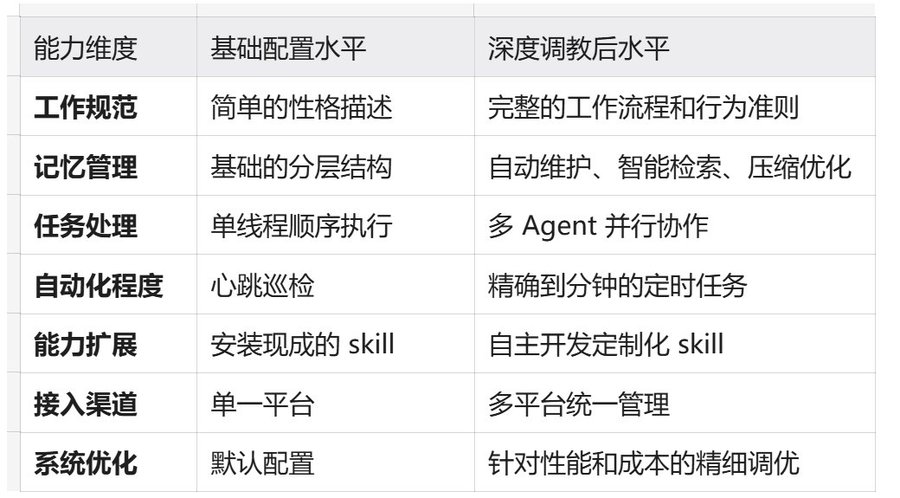
学习路线:从基础到进阶
推荐学习顺序
第一阶段:工作规范建立(30-60 分钟)
创建 AGENTS.md 工作手册
定义 session 启动流程
设置记忆写入规范
配置安全边界
第二阶段:记忆系统优化(60-120 分钟)
启用 memoryFlush 防止信息丢失
优化日志格式提升检索精度
配置自动维护机制
调整 embedding 模型
第三阶段:高级功能应用(120-240 分钟)
部署子 Agent 实现任务分发
创建 Cron 定时任务
开发自定义 Skill
配置多渠道接入
第四阶段:性能调优(1-2 天)
调整模型参数
优化 token 使用
配置缓存策略
监控系统性能
学习建议
循序渐进:不要跳过基础步骤,每个配置都有其作用
实践验证:每完成一个配置,立即测试验证效果
记录问题:遇到问题及时记录,便于后续排查
备份配置:重要修改前备份配置文件
核心配置:AGENTS.md AI打工守则
为什么需要 AGENTS.md
在基础教程中,我们创建了描述 AI 性格的 SOUL.md、描述用户信息的 USER.md、以及定义身份的 IDENTITY.md。但这些文件只解决了“AI 是谁”和“用户是谁”的问题,并没有告诉 AI“如何工作”。
AGENTS.md 的作用是定义 AI 的工作流程和行为准则,类似于员工手册。它告诉 AI:
每次启动时应该读取哪些文件
记忆应该如何组织和存储
哪些操作需要用户确认
如何处理不同类型的任务
类比说明:
SOUL.md → 个人性格档案
USER.md → 服务对象信息
IDENTITY.md → 身份标识
AGENTS.md → 工作流程手册
Session 启动配置
OpenClaw 每次启动新会话时都处于“初始状态”,需要通过读取文件来恢复记忆和上下文。合理的启动流程可以确保 AI 快速进入工作状态。
配置文件位置: workspace/AGENTS.md
启动流程配置:
Session 启动流程
每次会话开始时,按以下顺序自动执行:
1. 读取 `SOUL.md` - 加载性格和行为风格
2. 读取 `USER.md` - 了解用户背景和偏好
3. 读取 `memory/YYYY-MM-DD.md` - 加载今天和昨天的日志
4. 如果是主会话:额外读取 `MEMORY.md` - 加载核心记忆索引
以上操作无需询问,自动执行。配置说明:
步骤 1-2:加载基础信息 SOUL.md 和 USER.md 通常很小(<1KB),每次都读取不会造成性能负担。这两个文件确保 AI 知道自己的角色定位。
步骤 3:加载近期日志读取今天和昨天的日志文件,可以让 AI 快速了解最近发生的事情。之所以包含昨天的日志,是因为如果当前时间是凌晨,今天的日志可能还是空的。
步骤 4:条件加载核心记忆 MEMORY.md 可能包含敏感信息(如服务器配置、API 密钥等),因此只在主会话中加载。OpenClaw 支持多种会话类型:
主会话:用户直接对话(如 Discord 私聊、WebChat)
群聊会话:多人群组对话
子 Agent 会话:子任务执行会话
Cron 会话:定时任务触发的会话
AI 会自动识别当前会话类型,你只需在 AGENTS.md 中定义规则即可。
记忆管理规范
OpenClaw 的记忆系统采用分层设计,不同类型的信息存储在不同的文件中。在 AGENTS.md 中明确定义记忆管理规范,可以确保信息被正确归档。
记忆层级结构:
## Memory
You wake up fresh each session. These files are your continuity.
### 记忆分层
| 层级 | 文件 | 用途 |
| --- | --- | --- |
| 索引层 | `MEMORY.md` | 关于用户、能力概览、记忆索引。保持精简(<40行) |
| 项目层 | `memory/projects.md` | 各项目当前状态与待办 |
| 基础设施层 | `memory/infra.md` | 服务器、API、部署等配置速查 |
| 教训层 | `memory/lessons.md` | 踩过的坑,按严重程度分级 |
| 日志层 | `memory/YYYY-MM-DD.md` | 每日原始记录 |
### 写入规则
- **日志**:当天发生的事写入 `memory/YYYY-MM-DD.md`,格式:【项目:名称】 事件标题
**分层写入规则:**
- 当天发生的事情 → 写入 `memory/YYYY-MM-DD.md`
- 项目状态变更 → 同步更新 `memory/projects.md`
- 遇到问题和解决方案 → 记录到 `memory/lessons.md`
- 核心信息变更 → 更新 `MEMORY.md` 索引
**重要原则:**
- 记录结论而非过程
- 使用标签便于检索
- 保持 MEMORY.md 精简(<40 行)
- 想要记住的信息必须写入文件,不要依赖"记在脑子里"日志质量对比:
❌ 低质量日志示例:
### 今天的工作
今天配置了服务器,先试了方案 A 但是不行,报错了。然后又试了方案 B,
还是有问题。最后用了方案 C,花了两个小时终于搞定了。配置文件在
/etc/config/app.conf 里面。明天还要继续调试其他功能。✅ 高质量日志示例:
### [项目:WebApp] 服务器部署完成
- **结果**:使用 Nginx 反向代理部署成功,监听 443 端口
- **相关文件**:`/etc/nginx/sites-available/webapp.conf`
- **经验教训**:方案 A 和 B 失败原因是端口冲突,必须使用反向代理
- **检索标签**:#webapp #nginx #部署高质量日志的优势:
信息密度高,一眼就能看到关键结论
标签便于后续用 memorySearch 检索
结构化格式便于 AI 解析和理解
安全和权限边界
定义清晰的安全边界可以防止 AI 执行危险操作或泄露敏感信息。
## 安全规范
### 基本原则
- 不得泄露私人数据和敏感信息
- 执行破坏性操作前必须确认
- 删除文件使用 `trash` 而非 `rm`(可恢复优于永久删除)
- 不确定时,先询问用户
### 操作权限分类
**可以自由执行的操作:**
- 读取文件、浏览目录
- 搜索网络信息
- 查询日历和邮件
- 在 workspace 内部工作
**需要用户确认的操作:**
- 发送邮件、推文、公开消息
- 任何向外部发送数据的操作
- 删除或修改重要文件
- 不确定后果的操作
### 群聊行为规范
在群聊环境中:
- 你可以访问用户的文件和记忆,但不能在群聊中分享
- 你是群聊的参与者,而非用户的代言人
- 不要替用户发言或泄露用户的私人信息完整 AGENTS.md 模板
以下是可以直接使用的完整模板,保存为 workspace/AGENTS.md:
# AGENTS.md - 工作空间规范
这是你的工作空间,请按照以下规范工作。
## Session 启动流程
每次会话开始时,按以下顺序自动执行:
1. 读取 `SOUL.md` - 加载性格和行为风格
2. 读取 `USER.md` - 了解用户背景和偏好
3. 读取 `memory/YYYY-MM-DD.md` - 加载今天和昨天的日志
4. 如果是主会话:额外读取 `MEMORY.md` - 加载核心记忆索引
以上操作无需询问,自动执行。
## 记忆管理规范
你每次启动都是全新状态,这些文件是你的记忆延续。
| 层级 | 文件路径 | 存储内容 |
|------|---------|---------|
| 索引层 | `MEMORY.md` | 核心信息和记忆索引,保持精简 |
| 项目层 | `memory/projects.md` | 各项目当前状态和待办 |
| 经验层 | `memory/lessons.md` | 问题解决方案,按重要性分级 |
| 日志层 | `memory/YYYY-MM-DD.md` | 每日详细记录 |
### 写入规则
- 日志写入 `memory/YYYY-MM-DD.md`,记录结论而非过程
- 项目变更时同步更新 `memory/projects.md`
- 遇到问题时记录到 `memory/lessons.md`
- MEMORY.md 仅在索引变化时更新
- 重要信息必须写入文件,不要依赖记忆
### 日志格式
【项目:名称】 事件标题
结果:一句话概括
相关文件:文件路径
经验教训:要点(如有)
检索标签:#tag1 #tag2
## 安全规范
- 不得泄露私人数据
- 破坏性操作前必须确认
- 使用 `trash` 而非 `rm`
- 不确定时先询问
**可自由执行:** 读取文件、搜索、整理、在 workspace 内工作
**需要确认:** 发送邮件/消息、任何向外发送数据的操作
## 群聊规范
你可以访问用户的文件和记忆,但不能在群聊中分享。
在群聊中,你是参与者,不是用户的代言人。
## 工具使用
Skills 提供你的工具能力。需要使用某个工具时,查看其 SKILL.md 文档。📋 实践任务 1:创建 AGENTS.md
任务目标:
在 workspace 根目录创建 AGENTS.md 文件
复制上面的模板并根据你的实际需求调整
重启 OpenClaw 并验证配置是否生效
验证方法:
开启一个新会话
观察 AI 是否自动读取了指定的文件
让 AI 记录一件事,检查是否写入了正确的文件和格式
✅ 完成标准:
AGENTS.md 文件创建成功
AI 能够按照规范自动读取记忆文件
AI 写入的日志符合指定格式
记忆优化:构建可靠的记忆体系
现状分析
在完成基础教程后,你的 OpenClaw 已经具备了基本的记忆功能:
分层记忆结构(MEMORY.md + memory/*.md)
语义检索功能(memorySearch)
但在实际使用中,可能会遇到以下问题:
问题 1:长对话后 AI “失忆”当对话内容超过上下文窗口限制时,OpenClaw 会自动压缩旧对话,这个过程可能导致重要信息丢失。
问题 2:检索命中率不理想日志格式不统一、缺少标签、信息密度低,导致 memorySearch 难以找到相关内容。
问题 3:记忆文件缺乏维护随着时间推移,过期信息堆积,噪音增加,影响检索质量。
本章将逐一解决这些问题。
启用 memoryFlush 功能
问题场景:
你和 AI 进行了长时间的深度讨论,制定了重要决策。突然发现 AI 的回复开始变得“健忘”,好像忘记了之前讨论的内容。
原因分析:
每个 AI 模型都有上下文窗口限制(例如 Claude 是 200K tokens)。当对话接近这个限制时,OpenClaw 会触发自动压缩(compaction),将旧对话总结成摘要以腾出空间。压缩过程可能会丢失细节信息。
解决方案:
启用 memoryFlush 功能。该功能会在压缩触发前,先让 AI 将重要信息写入文件,然后再执行压缩。
工作流程:
OpenClaw 检测到上下文即将达到限制
触发 memoryFlush,提示 AI 保存重要信息
AI 将关键内容写入 memory/ 目录
执行压缩,清理旧对话
重要信息已持久化,不会丢失
配置方法:
编辑 openclaw.json,添加以下配置:
{
"agents": {
"defaults": {
"compaction": {
"reserveTokensFloor": 20000,
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 4000
}
}
}
}
}参数说明:

关于 softThresholdTokens:
这个值设置为 4000 意味着:当剩余空间不足 4000 tokens 时触发 memoryFlush。
太小(如 1000):AI 没有足够空间写入详细信息
太大(如 10000):会频繁触发,影响性能
4000 是经过测试的平衡值
效果验证:
启用后,即使进行长时间对话,AI 也能保持对之前讨论内容的记忆,因为关键信息已经持久化到文件中。
提示: memoryFlush 是静默执行的,不会打断对话。如果想查看触发情况,可以启用 verbose 模式(发送 /verbose 命令),会看到 Auto-compaction complete 的提示。
优化日志格式提升检索精度
memorySearch 使用向量语义检索技术,将搜索词和日志内容都转换为向量,然后计算相似度。
提升检索精度的关键因素:
实际效果对比:
假设搜索词为:“nginx 部署配置”
低效日志(命中率低):
今天工作内容:上午处理了数据库备份问题,中午部署了新版本应用,
下午修改了 nginx 配置,晚上写了一些文档。nginx 那边改了反向代理
的配置,具体记不太清了,反正最后跑起来了。问题:
包含多个不相关主题,稀释了向量相似度
缺少结构化信息,关键点不突出
没有标签,难以精准匹配
高效日志(命中率高):
### [项目:WebApp] Nginx 反向代理配置
- **结果**:成功配置 Nginx 反向代理,应用通过 443 端口访问
- **相关文件**:`/etc/nginx/sites-available/webapp.conf`
- **经验教训**:upstream 必须使用 127.0.0.1 而非 localhost(避免 IPv6 问题)
- **检索标签**:#nginx #deploy #webapp #reverse-proxy优势:
标题、结果、标签都包含搜索关键词
结构化格式使信息密度高
单一主题,向量表示更准确
配置自动记忆维护
问题:
随着使用时间增长,日志文件会不断累积。其中一些信息已经过期(如临时调试记录、已完成的一次性任务),这些“噪音”会干扰 memorySearch 的检索结果。
解决方案:
配置定期自动维护任务,让 AI 自己整理记忆。
实现方法:
在 workspace/HEARTBEAT.md 中添加维护任务:
## 记忆维护任务(每周执行)
检查 `memory/heartbeat-state.json` 中的 `lastMemoryMaintenance` 字段。
如果距今超过 7 天,执行以下维护流程:
1. 读取最近 7 天的日志文件 `memory/YYYY-MM-DD.md`
2. 提炼有长期价值的信息,归档到对应文件:
- 项目决策和状态 → `memory/projects.md`
- 问题解决方案 → `memory/lessons.md`
3. 压缩已完成的一次性任务为一行总结
4. 删除完全过期的临时信息
5. 更新 `heartbeat-state.json` 中的 `lastMemoryMaintenance` 为当前日期创建状态跟踪文件 workspace/memory/heartbeat-state.json:
{
"lastMemoryMaintenance": "2026-02-26"
}维护操作说明:
提炼(Extract):将日志中有长期价值的信息移动到对应的层级文件。
示例:日志中记录了一个项目的技术选型决策,应该提炼到 projects.md 中。
压缩(Compress):将已完成的详细任务记录压缩为简短的结论。
示例:
压缩前:详细记录了部署过程的 10 个步骤
压缩后:2026-02-17: 完成 WebApp 生产环境部署,使用 Nginx + Docker 方案
清理(Clean):删除完全过期的临时信息。
示例:
“明天要参加会议” → 会议已过,可以删除
“测试中的临时配置” → 测试已完成,可以删除
配置 Embedding 模型
memorySearch 依赖 embedding 模型将文本转换为向量。选择合适的模型可以提升检索质量并降低成本。
推荐配置:
{
"memorySearch": {
"enabled": true,
"provider": "openai",
"remote": {
"baseUrl": "https://api.siliconflow.cn/v1",
"apiKey": "你的_SiliconFlow_API_Key"
},
"model": "BAAI/bge-m3"
}
}为什么选择 bge-m3:
成本:SiliconFlow 提供免费额度,个人使用足够
多语言:对中英文混合文本支持良好
性能:向量维度 1024,在精度和速度间取得平衡
获取 SiliconFlow API Key:
访问 siliconflow.cn 注册账号
进入控制台,创建 API Key
免费额度:每天数百万 tokens,个人使用完全足够
memorySearch 工作流程:
用户提问:“上次 nginx 配置问题怎么解决的?”
AI 调用 memory_search(“nginx 配置问题”)
memorySearch 返回最相关的几条结果(包含文件路径和行号)
AI 调用 memory_get(path="memory/2026-02-18.md", from=47, lines=10)
AI 读取具体内容并回答用户
这种两步走的设计很高效:search 负责“定位”,get 负责“读取”,避免加载所有记忆文件。
📋 实践任务 2:优化记忆系统
任务目标:
启用 memoryFlush 功能
按照优化后的格式重写最近 3 条日志
配置自动维护任务
切换到 bge-m3 embedding 模型
验证方法:
进行一次长对话(超过 100 轮),观察是否出现失忆
使用 memorySearch 搜索之前记录的内容,检查命中率
等待一周后检查自动维护是否执行
✅ 完成标准:
memoryFlush 配置已启用
日志格式符合优化标准
自动维护任务配置完成
embedding 模型切换成功
子 Agent 应用:团队协作模式
什么是子 Agent
在基础配置中,OpenClaw 是单线程工作的:你提出一个任务,AI 从头到尾完成。但对于复杂任务,这种模式效率很低。
子 Agent 的概念:
子 Agent 是主 Agent 派生出的独立工作进程,可以并行执行不同的子任务。
类比:
单 Agent 模式:你是项目经理,所有工作都自己做
多 Agent 模式:你是项目经理,可以派遣团队成员并行工作
适用场景
场景 1:信息收集任务
任务:收集 5 个竞品的功能对比
单 Agent:顺序访问 5 个网站,耗时 10 分钟
多 Agent:派 5 个子 Agent 并行收集,耗时 2 分钟
场景 2:数据处理任务
任务:分析 100 个文件的内容
单 Agent:逐个处理,耗时很长
多 Agent:分配给 10 个子 Agent,每个处理 10 个文件
场景 3:监控任务
任务:同时监控多个服务的状态
单 Agent:轮询检查,响应慢
多 Agent:每个服务分配一个监控 Agent
配置子 Agent
基础配置:
编辑 openclaw.json:
{
"agents": {
"defaults": {
"subAgents": {
"enabled": true,
"maxConcurrent": 3,
"timeout": 300000
}
}
}
}参数说明:

关于 maxConcurrent:
这个值不是越大越好:
太小(如 1):无法发挥并行优势
太大(如 10):可能触发 API 速率限制,增加成本
推荐 3-5:在性能和成本间取得平衡
使用子 Agent
方法 1:自动派遣
AI 会自动判断任务是否适合并行处理。
示例对话:
用户:帮我收集这 5 个网站的主要功能:[网站列表]
AI:我将派遣 5 个子 Agent 并行收集信息...
[子 Agent 1] 正在分析网站 A...
[子 Agent 2] 正在分析网站 B...
...
所有信息已收集完成,正在整理汇总...方法 2:显式指定
你也可以明确要求使用子 Agent:
用户:使用子 Agent 并行处理这个任务...子 Agent 最佳实践
任务分解要合理
好的分解:
将“分析 100 个文件”分解为 10 个子任务,每个处理 10 个文件
不好的分解:
将“写一篇文章”分解为多个子任务(写作需要连贯性,不适合并行)
设置合理的超时时间
根据任务复杂度调整 timeout:
简单查询:60 秒
数据分析:5 分钟
复杂处理:10 分钟
监控并发数
使用 /status 命令查看当前运行的子 Agent 数量,避免过载。
成本控制
子 Agent 会增加 API 调用次数,注意监控成本。
📋 实践任务 3:子 Agent 实战
任务目标:
启用子 Agent 功能
完成一个并行任务(如信息收集)
观察执行效率提升
练习任务:
选择以下任务之一进行练习:
收集 5 个竞品的定价信息
分析 10 个网页的关键词
检查 5 个服务的在线状态
✅ 完成标准:
子 Agent 配置已启用
成功完成至少一个并行任务
理解子 Agent 的适用场景
定时任务:Cron 自动化实践
Cron 任务概述
Cron 是 OpenClaw 的定时任务功能,可以让 AI 在指定时间自动执行任务,无需人工触发。
典型应用场景:
每日简报:每天早上发送天气、日程、新闻摘要
定期备份:每周自动备份重要文件
监控告警:每小时检查服务状态,异常时通知
定时提醒:工作日下午 6 点提醒结束工作
创建 Cron 任务
方法 1:通过对话创建
用户:创建一个定时任务,每天早上 8 点发送今日简报
AI:我将为你创建定时任务...
- 任务名称:daily-briefing
- 执行时间:每天 08:00
- 任务内容:发送天气、日程、新闻摘要
已创建成功!方法 2:手动配置
编辑 workspace/crons/daily-briefing.json:
{
"name": "daily-briefing",
"schedule": "0 8 * * *",
"timezone": "Asia/Shanghai",
"task": {
"type": "message",
"content": "发送今日简报:天气、日程、重要新闻"
},
"enabled": true
}Cron 表达式说明:
格式:分钟 小时 日期 月份 星期
常用示例:
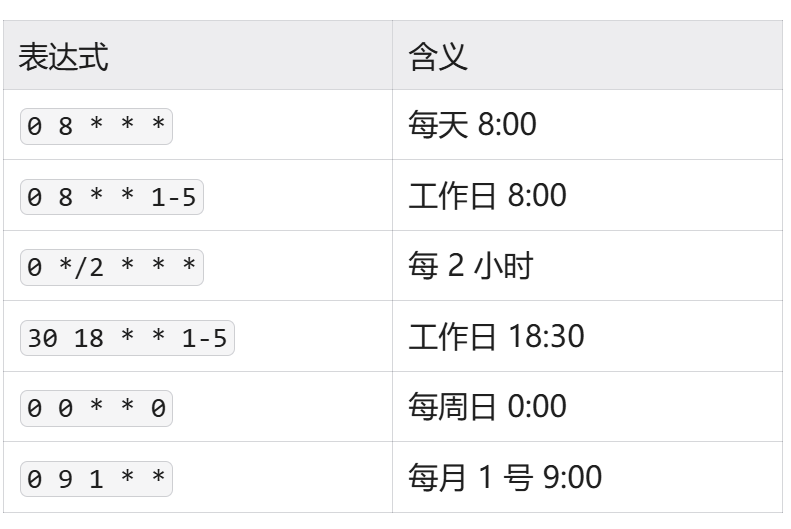
在线工具:crontab.guru 可以帮助你生成和验证 cron 表达式。
Cron 任务示例
示例 1:每日早报
{
"name": "morning-briefing",
"schedule": "0 8 * * *",
"timezone": "Asia/Shanghai",
"task": {
"type": "message",
"content": "早安!今日简报:
1. 查询天气
2. 读取今日日程
3. 总结昨日工作日志
4. 提醒今日待办事项"
},
"enabled": true
}示例 2:工作日晚间提醒
{
"name": "evening-reminder",
"schedule": "0 18 * * 1-5",
"timezone": "Asia/Shanghai",
"task": {
"type": "message",
"content": "工作日结束提醒:
1. 总结今日完成的任务
2. 记录未完成事项
3. 规划明日工作"
},
"enabled": true
}示例 3:每周总结
{
"name": "weekly-summary",
"schedule": "0 17 * * 5",
"timezone": "Asia/Shanghai",
"task": {
"type": "message",
"content": "周五晚间总结:
1. 回顾本周工作日志
2. 统计完成的任务数量
3. 整理下周计划"
},
"enabled": true
}示例 4:服务监控
{
"name": "service-monitor",
"schedule": "*/30 * * * *",
"timezone": "Asia/Shanghai",
"task": {
"type": "check",
"content": "检查以下服务状态:
1. 网站是否可访问
2. API 响应时间
3. 数据库连接
如有异常立即通知"
},
"enabled": true
}管理 Cron 任务
查看所有任务:
查看所有任务:
openclaw cron list启用/禁用任务:
openclaw cron enable daily-briefing
openclaw cron disable daily-briefing删除任务:
openclaw cron remove daily-briefing手动触发任务(测试用):
openclaw cron run daily-briefingCron 任务最佳实践
合理设置执行频率
不要过于频繁(如每分钟执行),会增加成本
根据实际需求设置(监控可以 5-10 分钟,简报每天一次即可)
设置时区
确保 timezone 字段设置正确,否则任务可能在错误的时间执行。
任务内容要具体
不要写“发送简报”,而要写“发送简报:天气、日程、新闻”,让 AI 知道具体要做什么。
测试后再启用
创建任务后,先用 openclaw cron run 手动触发测试,确认无误后再启用自动执行。
监控执行日志
定期检查 workspace/logs/cron.log,确认任务正常执行。
📋 实践任务 4:创建定时任务
任务目标:
创建至少 2 个 Cron 任务
测试任务是否正常执行
观察一周的自动化效果
推荐任务:
每日早报(早上 8 点)
工作日晚间提醒(下午 6 点)
每周总结(周五下午)
✅ 完成标准:
成功创建至少 2 个 Cron 任务
手动触发测试通过
任务已启用并自动执行
Skill 开发:扩展 AI 能力
Skill 系统概述
Skill 是 OpenClaw 的能力扩展机制,类似于插件或应用。每个 Skill 定义了一组特定的任务和工作流程。
Skill 的作用:
封装复杂的工作流程
定义专业领域的任务模板
提供可复用的能力模块
Skill 类型:
官方 Skill:OpenClaw 团队维护的标准 Skill
社区 Skill:用户分享的第三方 Skill
自定义 Skill:你自己开发的 Skill
Skill 文件结构
一个标准的 Skill 包含以下文件:
workspace/skills/my-skill/
├── SKILL.md # Skill 说明文档
├── config.json # 配置文件
└── templates/ # 模板文件(可选)创建简单 Skill
示例:天气查询 Skill
创建文件 workspace/skills/weather-check/SKILL.md:
# 天气查询 Skill
## 功能描述
查询指定城市的天气信息并格式化输出。
## 使用方法
用户:查询北京天气
AI 执行流程:
1. 调用天气 API 获取数据
2. 提取关键信息:温度、天气状况、空气质量
3. 格式化输出
## 输出格式
📍 北京天气
🌡️ 温度:15°C
☁️ 天气:多云
💨 风力:3 级
🌫️ 空气质量:良
## 配置要求
需要配置天气 API Key:
- 提供商:OpenWeatherMap
- 配置路径:config.json创建配置文件 workspace/skills/weather-check/config.json:
{
"name": "weather-check",
"version": "1.0.0",
"description": "查询城市天气信息",
"author": "你的名字",
"config": {
"apiKey": "你的_API_Key",
"apiUrl": "https://api.openweathermap.org/data/2.5/weather",
"defaultCity": "Beijing"
}
}安装和使用 Skill
安装 Skill:
openclaw skill install ./workspace/skills/weather-check使用 Skill:
用户:使用天气查询 Skill 查询上海天气
AI:正在调用天气查询 Skill...
📍 上海天气
🌡️ 温度:18°C
☁️ 天气:晴
💨 风力:2 级
🌫️ 空气质量:优高级 Skill 示例
示例:任务管理 Skill
创建 workspace/skills/task-manager/SKILL.md:
# 任务管理 Skill
## 功能
- 添加任务
- 查看任务列表
- 标记任务完成
- 删除任务
## 数据存储
任务存储在 `workspace/data/tasks.json`
## 命令格式
- 添加任务:`添加任务:[任务描述]`
- 查看任务:`查看任务` 或 `任务列表`
- 完成任务:`完成任务:[任务 ID]`
- 删除任务:`删除任务:[任务 ID]`
## 工作流程
### 添加任务
1. 解析任务描述
2. 生成唯一 ID
3. 添加到 tasks.json
4. 确认添加成功
### 查看任务
1. 读取 tasks.json
2. 按状态分类(进行中/已完成)
3. 格式化输出
### 完成任务
1. 查找任务 ID
2. 更新状态为"已完成"
3. 记录完成时间
4. 保存并确认Skill 开发最佳实践
清晰的文档
SKILL.md 应该包含:
功能描述
使用方法
配置要求
示例输出
合理的配置
将可变参数放在 config.json 中,便于用户自定义。
错误处理
考虑异常情况:
API 调用失败
配置缺失
数据格式错误
版本管理
在 config.json 中记录版本号,便于更新和维护。
测试验证
开发完成后充分测试,确保各种场景下都能正常工作。
📋 实践任务 5:开发自定义 Skill
任务目标:
开发一个简单的自定义 Skill
安装并测试 Skill
完善文档和配置
推荐项目:
选择以下之一进行开发:
倒计时 Skill:计算距离某个日期还有多少天
笔记 Skill:快速记录和查询笔记
提醒 Skill:设置和管理提醒事项
统计 Skill:统计工作日志中的关键数据
✅ 完成标准:
成功创建一个自定义 Skill
Skill 能正常工作
文档完整清晰
多渠道部署:全平台接入方案
多渠道接入概述
OpenClaw 支持同时接入多个消息平台,实现“一个 AI,多处可用”的效果。
支持的平台:
即时通讯:Telegram、Discord、Slack、WhatsApp
社交媒体:Twitter、微信(通过第三方桥接)
Web 接口:WebChat、HTTP API
本地接口:CLI 命令行
配置多渠道接入
基础配置文件: openclaw.json
{
"gateways": {
"telegram": {
"enabled": true,
"token": "你的_Telegram_Bot_Token"
},
"discord": {
"enabled": true,
"token": "你的_Discord_Bot_Token",
"allowedChannels": ["channel-id-1", "channel-id-2"]
},
"webchat": {
"enabled": true,
"port": 3000,
"auth": {
"enabled": true,
"password": "你的密码"
}
}
}
}Telegram 接入配置
步骤 1:创建 Bot
在 Telegram 中搜索 @BotFather
发送 /newbot 命令
按提示设置 Bot 名称和用户名
获取 Bot Token
步骤 2:配置 OpenClaw
{
"gateways": {
"telegram": {
"enabled": true,
"token": "你的_Bot_Token",
"allowedUsers": ["你的_Telegram_User_ID"]
}
}
}步骤 3:启动并测试
重启 OpenClaw
在 Telegram 中搜索你的 Bot
发送 /start 开始对话
Discord 接入配置
步骤 1:创建 Discord 应用
创建新应用
在 Bot 页面创建 Bot 并获取 Token
在 OAuth2 页面生成邀请链接,添加 Bot 到服务器
步骤 2:配置 OpenClaw
{
"gateways": {
"discord": {
"enabled": true,
"token": "你的_Discord_Bot_Token",
"allowedChannels": ["频道_ID"],
"commandPrefix": "!"
}
}
}步骤 3:测试
在 Discord 频道中发送 ! help 测试 Bot 是否响应。
WebChat 接入配置
WebChat 提供浏览器访问界面,适合本地使用。
配置:
{
"gateways": {
"webchat": {
"enabled": true,
"port": 3000,
"host": "localhost",
"auth": {
"enabled": true,
"username": "admin",
"password": "你的密码"
},
"https": {
"enabled": false
}
}
}
}访问:
启动后访问 http://localhost:3000 即可使用 Web 界面。
消息路由配置
当接入多个平台时,可以配置消息路由规则,让不同类型的消息发送到不同平台。
示例配置:
{
"routing": {
"rules": [
{
"type": "alert",
"destinations": ["telegram", "discord"]
},
{
"type": "daily-briefing",
"destinations": ["telegram"]
},
{
"type": "log",
"destinations": ["file"]
}
]
}
}规则说明:
告警消息同时发送到 Telegram 和 Discord
每日简报只发送到 Telegram
日志消息只写入文件
多渠道最佳实践
权限隔离
不同平台设置不同的权限:
Telegram(个人):完全权限
Discord(团队):限制敏感操作
WebChat(公开):只读权限
消息分类
根据消息类型选择合适的平台:
紧急告警 → Telegram(推送通知)
日常交互 → Discord(团队协作)
数据查询 → WebChat(可视化界面)
成本控制
多渠道会增加 API 调用,注意监控成本。
📋 实践任务 6:配置多渠道接入
任务目标:
配置至少 2 个消息平台
测试跨平台消息同步
配置消息路由规则
推荐配置:
Telegram(个人使用)
Discord 或 WebChat(团队/本地使用)
✅ 完成标准:
成功配置至少 2 个平台
能在不同平台与 AI 对话
消息路由规则生效
性能调优:配置参数详解
模型选择和配置
不同任务适合不同的模型,合理选择可以平衡性能和成本。
推荐配置:
{
"agents": {
"defaults": {
"model": {
"provider": "anthropic",
"name": "claude-3-5-sonnet-20241022",
"temperature": 0.7,
"maxTokens": 4096
},
"fallback": {
"enabled": true,
"models": [
{
"provider": "openai",
"name": "gpt-4o"
}
]
}
}
}
}参数说明:
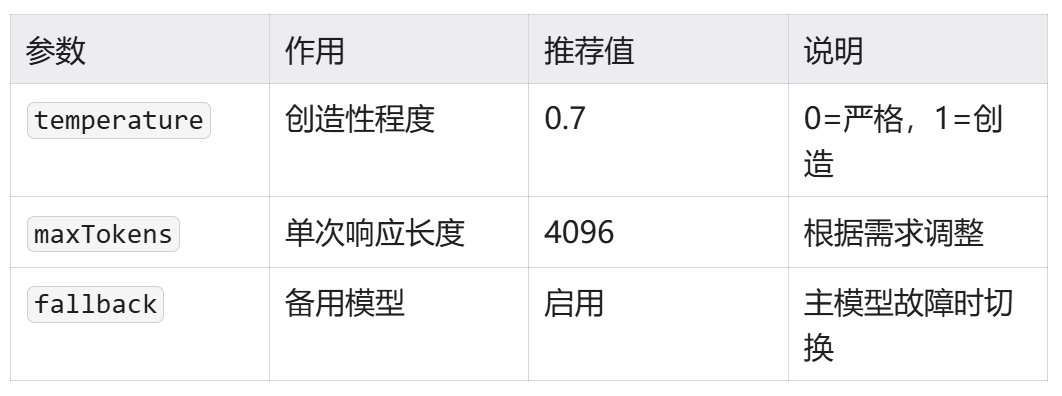
temperature 选择建议:
0.3-0.5:代码生成、数据分析(需要精确)
0.7-0.8:日常对话、内容创作(平衡)
0.9-1.0:创意写作、头脑风暴(创造性)
Token 使用优化
Token 是 API 成本的主要来源,优化 token 使用可以显著降低费用。
优化策略:
启用缓存
{
"agents": {
"defaults": {
"cache": {
"enabled": true,
"ttl": 3600,
"maxSize": 100
}
}
}
}缓存可以避免重复的 API 调用,特别是对于相同或相似的查询。
压缩系统提示
将冗长的系统提示精简为关键要点,减少每次调用的固定成本。
使用更便宜的模型
对于简单任务,使用较便宜的模型:
{
"agents": {
"simple-tasks": {
"model": {
"provider": "openai",
"name": "gpt-4o-mini"
}
}
}
}限制上下文长度
{
"agents": {
"defaults": {
"compaction": {
"targetTokens": 50000
}
}
}
}性能监控
启用详细日志:
{
"logging": {
"level": "info",
"file": "workspace/logs/openclaw.log",
"metrics": {
"enabled": true,
"interval": 3600
}
}
}查看使用统计:
openclaw stats --period 7d输出示例:
OpenClaw 使用统计(最近 7 天)
API 调用:
- 总次数:1,234
- 总 tokens:456,789
- 估算成本:$12.34
模型分布:
- claude-3-5-sonnet:80%
- gpt-4o:15%
- gpt-4o-mini:5%
任务类型:
- 对话:60%
- 文件操作:25%
- 网络搜索:15%成本控制
设置每日限额:
{
"billing": {
"limits": {
"daily": 10.00,
"monthly": 200.00
},
"alerts": {
"enabled": true,
"thresholds": [0.5, 0.8, 0.95]
}
}
}当使用量达到阈值(50%、80%、95%)时,系统会发送告警。
配置速查表
基础配置:
{
"agents": {
"defaults": {
"model": {
"provider": "anthropic",
"name": "claude-3-5-sonnet-20241022",
"temperature": 0.7,
"maxTokens": 4096
},
"compaction": {
"reserveTokensFloor": 20000,
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 4000
}
},
"subAgents": {
"enabled": true,
"maxConcurrent": 3,
"timeout": 300000
},
"cache": {
"enabled": true,
"ttl": 3600
}
}
},
"memorySearch": {
"enabled": true,
"provider": "openai",
"remote": {
"baseUrl": "https://api.siliconflow.cn/v1",
"apiKey": "你的_API_Key"
},
"model": "BAAI/bge-m3"
},
"logging": {
"level": "info",
"metrics": {
"enabled": true
}
},
"billing": {
"limits": {
"daily": 10.00,
"monthly": 200.00
}
}
}📋 实践任务 7:性能优化
任务目标:
根据你的使用情况优化配置
启用性能监控
设置成本控制
观察一周的优化效果
优化清单:
调整 temperature 参数
启用缓存
配置备用模型
设置每日限额
启用使用统计
✅ 完成标准:
配置已优化
成本控制已设置
能查看使用统计
实战练习清单
基础配置(必做)
任务 1:创建 AGENTS.md 工作规范
任务 2:优化记忆系统(memoryFlush + 日志格式)
任务 3:配置子 Agent 并完成并行任务
任务 4:创建至少 2 个 Cron 定时任务
任务 5:开发一个自定义 Skill
任务 6:配置多渠道接入(至少 2 个平台)
任务 7:性能优化和成本控制
进阶项目(推荐)
项目 1:构建自动化早报系统
每天早上发送天气、日程、新闻摘要
整合多个数据源
格式化输出
项目 2:邮件自动分类系统
自动读取新邮件
按重要性分类
自动回复常见问题
项目 3:多平台消息聚合
统一管理多个平台的消息
智能路由和转发
消息归档和搜索
项目 4:服务监控告警系统
定期检查服务状态
异常时自动告警
生成监控报告
项目 5:知识库管理系统
自动整理和归档笔记
智能检索和推荐
定期生成总结
高级挑战(可选)
挑战 1:开发复杂的多步骤 Skill
挑战 2:实现跨平台的工作流自动化
挑战 3:构建个人数据分析仪表板
挑战 4:集成第三方 API 和服务
挑战 5:优化到极致的成本控制(月费用 <$10)
疑难解答
Q1:memoryFlush 没有触发怎么办?
可能原因:
配置未正确启用
对话长度未达到触发阈值
日志级别过低,看不到触发信息
解决方法:
检查 openclaw.json 中 memoryFlush.enabled 是否为 true
启用 verbose 模式:发送 /verbose 命令
进行长对话测试(100+ 轮)观察是否触发
Q2:子 Agent 执行失败
可能原因:
并发数超过 API 限制
子任务超时
任务分解不合理
解决方法:
降低 maxConcurrent 值
增加 timeout 时间
检查任务是否适合并行处理
Q3:Cron 任务没有执行
可能原因:
Cron 表达式错误
时区设置不正确
任务被禁用
解决方法:
使用 crontab.guru 验证表达式
检查 timezone 字段
运行 openclaw cron list 查看任务状态
手动触发测试:openclaw cron run 任务名
Q4:memorySearch 检索不到内容
可能原因:
Embedding 模型未配置
日志格式不规范
缺少标签
解决方法:
检查 memorySearch 配置
按照优化格式重写日志
添加相关标签
Q5:多渠道消息不同步
可能原因:
路由规则配置错误
某个平台连接失败
权限设置不一致
解决方法:
检查 routing 配置
查看各平台的连接状态
统一权限设置
Q6:API 成本过高
解决方法:
启用缓存减少重复调用
对简单任务使用更便宜的模型
优化系统提示减少固定成本
设置每日限额防止超支
定期检查使用统计,找出高消耗点
Q7:配置文件修改后不生效
解决方法:
重启 OpenClaw:openclaw restart
检查 JSON 格式是否正确(使用 JSON 验证工具)
查看日志文件是否有错误信息
进阶学习资源
官方资源
官方网站:openclaw.ai
GitHub 仓库:github.com/openclaw/openclaw
官方文档:docs.openclaw.ai
社区资源
Reddit:r/clawdbot、r/AiForSmallBusiness
Discord:OpenClaw 官方 Discord 服务器
GitHub Discussions:在仓库的 Discussions 区提问和交流
中文资源
中文社区:MaoTouHU/OpenClawChinese(提供中文界面和文档)
中文教程:搜索“OpenClaw 中文教程”可以找到更多本地化资源
进阶主题
完成本教程后,你可以探索以下高级主题:
多 Agent 协作:让多个 Agent 协同工作
自定义插件开发:开发更复杂的功能扩展
企业级部署:在团队或公司中部署 OpenClaw
安全加固:深度配置安全策略
性能调优:针对大规模使用的优化
总结
完成本教程后,你的 OpenClaw 已经从“好用”提升到“更好用”,甚至“离不开”的水平。
你已经掌握:
✅ 完整的工作规范体系(AGENTS.md)
✅ 可靠的记忆管理机制
✅ 高效的任务并行处理
✅ 精确的定时自动化
✅ 自主的能力扩展
✅ 全平台的接入方案
✅ 优化的性能配置
下一步建议:
深入实践:选择一个实战项目,将所学知识应用到实际场景
持续优化:根据使用情况不断调整配置
参与社区:分享你的经验,帮助其他用户
探索创新:尝试开发独特的 Skill 和工作流
OpenClaw 的潜力远不止于此。随着你对系统的深入理解,你会发现更多可能性。
祝你在 AI 助手的探索之旅中收获满满!🚀
朋友,写文不易,看到这了,给个点赞书签再走?
最后更新:2026 年 2 月版本:2.0 适用于:OpenClaw v2.23 及以上版本